深入Mysql之(一)你真的了解索引?
一、索引的原理
Mysql我相信大部分人都接触过,但是很多人刚刚开始使用Mysql时,都是随便建表,一堆查询条件瞎搞的。代码日久未生情,却生出了一堆问题,过度使用Mysql与不合理使用索引,往往会导致慢查询等性能问题。 能区分一个低级与高级程序员的关键,就是看他是否能够掌握一门软件的原理,从而合理分析并使用它。
查询应该是CRUD中最为频繁的操作,如果是你会怎么来选择查询算法?顺序查询显然是不现实的,二分查找(binary search)、二叉树查找(binary tree search)也许是不错的选择,但是我们要知道,不同的查询算法,也是要对应不同的数据结构的,尚且不可能用一个简单的查找算法来实现,这样是远远不够的。
所以我们需要设计一个优秀的数据结构,来实现高效的查询算法,而这个数据结构就是我们所说的索引(Index),即用来帮助MySQL高效获取数据的数据结构。
二、聊聊B+树
目前大部分数据库系统及文件系统,都是采用B-Tree或其变种B+Tree作为索引结构。下图简单展示了数据库系统的索引结构:
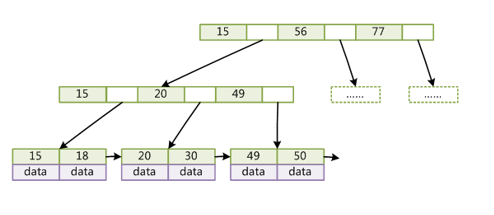
在B+树的基础上,增加了顺序访问指针。那么为什么我们要用这个数据结构呢,为什么不是用红黑树?
(1)索引本身也是很大的,需要存在磁盘中,那么我们要做的就是减少磁盘I/O次数;
(2)根据B树的定义,可知检索一次最多需要访问h个节点。主存和磁盘是以页为单位交换数据,这样的话,我们将一个节点的大小设为等于一个页大小,这样每个节点不就只需要一次I/O就可以完全载入吗?
(3)B+树相对是一个扁平的数据结构,它的深度h一般要远低于红黑树的。
举个例子,现在假设上面的图中,我们需要输出大于等于18的所有数字:
(1)首先我们从第一层根节点看到,15——56之间满足上面的情况,我们从这里继续往下走;
(2)非叶子节点,所以第二层依然为索引。目标数字18是在15到20之间,继续向下;
(3)到达叶子节点了,第一个节点中的值为15、18,终于找到18了!那么我们可以推测,后面的数字一定大于18了;
(4)此时无需再次回到上一层,因为顺序访问指针,已经帮我们指向了下一个比18大的数字,剩下要做的,就是一个个输出他们;
对于上面的索引本质的探究,推荐大家可以参看这篇文章。
三、MyISAM和InnoDB
众所周知,Mysql支持很多种存储引擎,其中MyISAM和InnoDB是使用的最为频繁的。
(1)MyISAM索引
MyISAM引擎使用B+树作为索引结构,叶节点的data域存放的是数据记录的地址,我们称MyISAM的索引方式也叫做非聚集(Non-clustered)的。
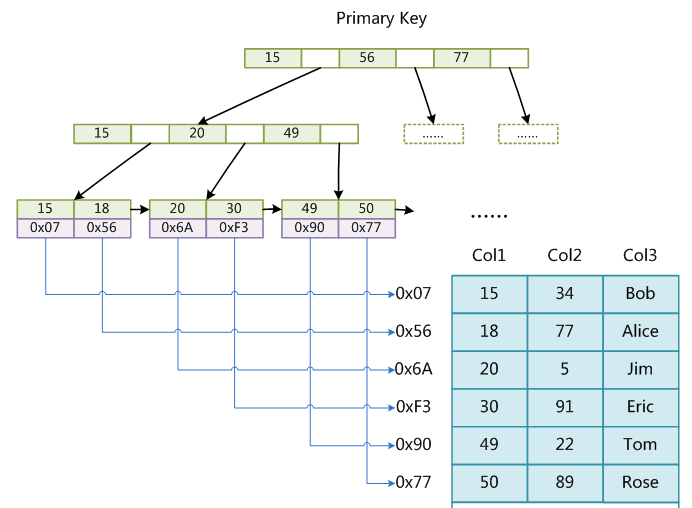
(2)InnoDB索引
InnoDB的数据文件本身就是索引文件,表数据文件本身就是按B树组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。还有一点很重要,InnoDB的辅助索引data域,存储相应记录主键的值,而不是地址。换句话讲,在叶子节点上存储的是主键的值,所以一般最好设置主键为一个整型id比较好,并且这也就代表了用辅助索引来查询时,需要先查到主键,再用主键索引查询到值,一共两次。
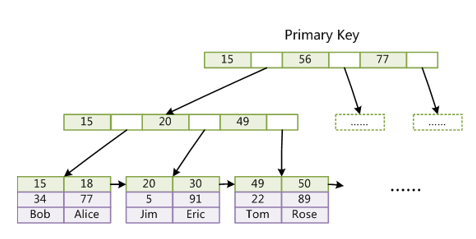
四、索引优化
(1)聚合索引
我们要先来说下什么是Clustered Index。聚合(联合)索引,顾名思义就是用一个组把几个列整合为一个索引,而MyISAM是非聚集的,所以我们使用InnoDB来举例。我们建一张表:
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`sex` varchar(128) NOT NULL DEFAULT 'male',
`name` varchar(128) NOT NULL DEFAULT '',
`grade` int(11) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `cluster_index` (`grade`,`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
可以通过命令来展示表的索引:
show index from student;

其中,cluster_index便是一个聚合索引。
下面我将用explain关键字,结合一个典型的例子来对我们的查询语句进行分析。
我们使用这个语句尝试一下:
explain select * from student where grade=3 and name="Tom" and age=10;
 效果是相同的,从key这列结果可以看到,cluster_index被引用到了,key_len为138,这里我们把where后面的条件位置随意倒换也不会影响查询的效果,因为Mysql帮我们已经做了查询的优化。
效果是相同的,从key这列结果可以看到,cluster_index被引用到了,key_len为138,这里我们把where后面的条件位置随意倒换也不会影响查询的效果,因为Mysql帮我们已经做了查询的优化。
我们把条件列尝试去掉其中一个试试,去掉name:
explain select * from student where grade=3 and age=10;
 cluster_index还是被引用到了,但是key_len变成了4,说明了查询只用到了索引的第一列前缀,和单独以grade为条件的效果是一样的。
cluster_index还是被引用到了,但是key_len变成了4,说明了查询只用到了索引的第一列前缀,和单独以grade为条件的效果是一样的。
去掉age:
explain select * from student where grade=3 and name="Tom";
试试like的效果:
explain select * from student where grade=3 and name like "Tom%" ;
 两个效果相同,cluster_index还是被引用到了,但是key_len变成了134,说明了查询用到了索引第一、二列前缀。
两个效果相同,cluster_index还是被引用到了,但是key_len变成了134,说明了查询用到了索引第一、二列前缀。
那么,去掉最左边的grade呢:
explain select * from student where age=10 and name="Tom";

GG,由于没有最左前缀列被引用到,你可以看到没有索引被引用。最左前缀这个概念就大致是这样了,如果在聚合索引中,sql语句没有引用到最左前缀列,那么这个索引是不会被引用的。
另外要说明的是,对于范围搜索而言,也是一样的:
explain select * from student where grade>3 and name = "Tom";

缺少最左前缀列时:
explain select * from student where age>3 and name = "Tom";

(2)单列索引
我们新建一张表:
CREATE TABLE `student2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`sex` varchar(128) NOT NULL DEFAULT 'male',
`name` varchar(128) NOT NULL DEFAULT '',
`grade` int(11) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `i_grade` (`grade`),
KEY `i_name` (`name`),
KEY `i_age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
这个就比较好理解了,其中i_grade、i_name、i_age都可以称作单列索引。
那么是否一张表为了提升查询性能效率,就疯狂加索引呢? ——显然不是,回顾上面的内容,索引本身是文件,要消耗存储空间。对于辅助索引而言更是要存储索引与主键的映射,同时每次插入删除时,我们需要移动索引的排序和位置,久而久之会产生大量的碎片导致空间不连续,降低表的查询性能,MySQL在运行时也要消耗资源维护索引。
(3)优化建议
针对一些实际的应用问题,结合踩过的坑,我有下面几点建议:
a) 对于InnoDB引擎,一定要使用一个业务无关的自增ID字段作为表的主键。有很多人喜欢使非自增ID作为主键,这绝对是一个糟糕的设计,结合B+树的特性,在写表时节点需要频繁的移动,缺少递增的主键容易使得索引的结构松散,从而产生大量的碎片和空间浪费;
b) 针对频繁写操作且数据量较大的表,要定时进行表的Optimize操作:InnoDB使用语句: ALTER TABLE table_name ENGINE = Innodb,MyISAM引擎使用Optimize table xxx语句;
c) 对于数据量较小的表(千百行),不需要索引,只需要做全表扫描;
d)不要在查询条件中加表达式与函数,这样无法引用索引;
以上就是我对Mysql索引的一些愚见,如果有任何的问题,欢迎联系我&交流指教。