聊聊Java的GC机制

使用Java快一年时间了,从最早大学时候对Java的憎恶,到逐渐接受,到工作中体会到了Java开发的各种便捷与福利,这确实是一门不错的开发语言。不仅是Intellij开发Java程序的爽快,还有无需手动管理内存的便捷、Maven管理依赖的整洁、SpringCloud(SpringBoot)大礼包的规整等等。
所以,作为一个有追求的Java程序员,深入底层掌握GC(垃圾回收)的机制,应该算是必备的技能了。本文即我在学习过程中的一些个人观点以及心得,不正之处敬请指正。

一、 JVM的运行数据区
首先我简单来画一张JVM的结构原理图:
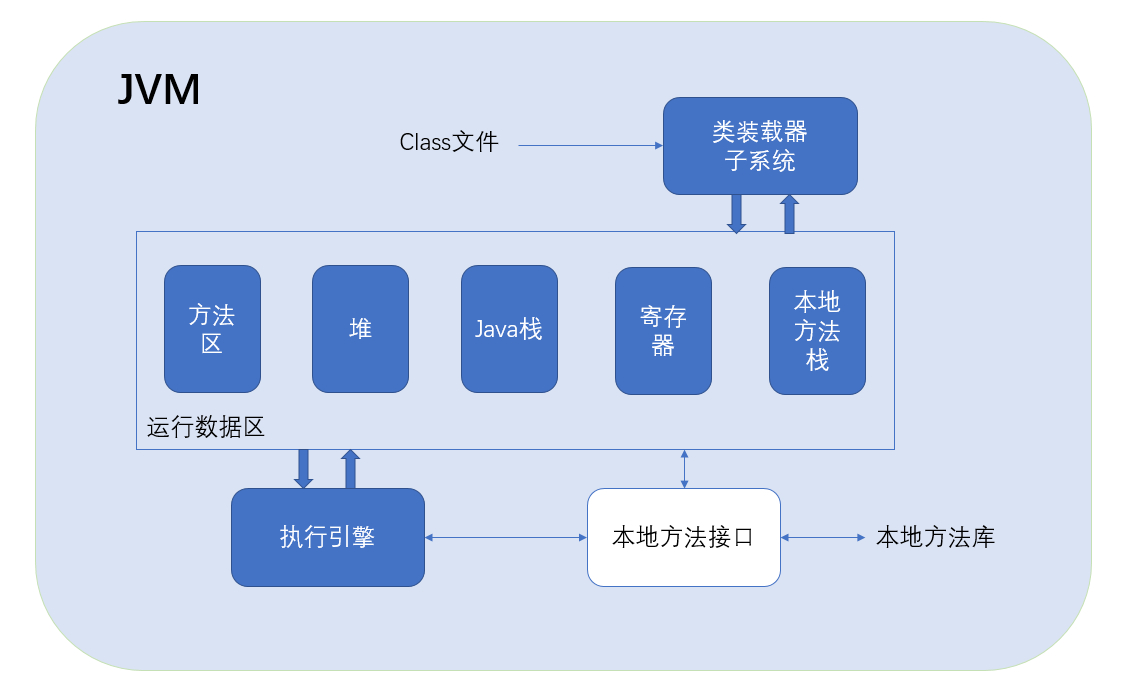
我们重点关注JVM在运行时的数据区,你可以看到在程序运行时,大致有5个部分:
(1)方法区
不止是存“方法”,而是存储整个class文件的信息,JVM运行时,类加载器子系统将会提取class文件里面的类信息,并将其存放在方法区中。例如类的名称、类的类型(枚举、类、接口)、字段、方法等等。
(2)堆(Heap)
熟悉c/c++编程的同学们应该相当熟悉Heap了,而对于Java而言,每个应用都唯一对应一个JVM实例,而每一个JVM实例唯一对应一个堆。堆主要包括关键字new的对象实例、this指针,或者数组都放在堆中,并由应用所有的线程共享。堆由JVM的自动内存管理机制所管理,名为垃圾回收——GC(garbage collection)。
(3)栈(Stack)
操作系统内核为某个进程或者线程建立的存储区域,它保存着一个线程中的方法的调用状态,它具有先进后出的特性。在栈中的数据大小与生命周期严格来说都是确定的,例如在一个函数中声明的int变量便是存储在stack中,它的大小是固定的,在函数退出后它的生命周期也从此结束。在栈中,每一个方法对应一个栈帧,JVM会对Java栈执行两种操作: 压栈和出栈。 这两种操作在执行时都是以栈帧为单位的。还有一些常量、静态变量、即时编译器编译后的代码等数据。
(4)PC寄存器
pc寄存器用于存放一条指令的地址,每一个线程都有一个PC寄存器。
(5)本地方法栈
用来调用其他语言的本地方法,例如C/C++写的本地代码, 这些方法在本地方法栈中执行,而不会在Java栈中执行。
二、初识GC
自动垃圾回收机制,简单来说就是寻找Java堆中的无用对象。打个比方:你的房间是JVM的内存,你在房间里生活会制造垃圾和脏乱,而你妈就是在对你的房间GC。你妈每时每刻都觉得你房间很脏乱,不时要把你赶出门打扫房间,如果你妈一直在房间打扫,那么这个过程你无法继续在房间打游戏吃泡面。但如果你一直在房间,你的房间早晚要变成一个无法居住的猪窝。
那么,怎么样回收垃圾比较好呢?我们大致可以想出下面的思路:
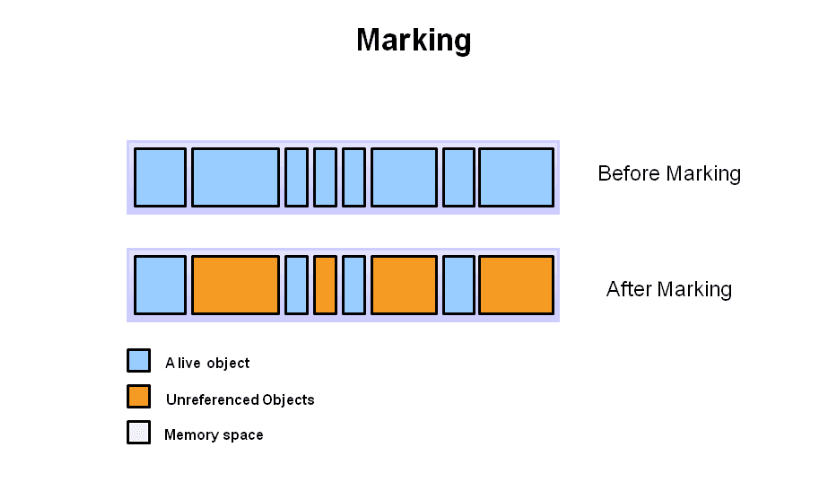
(1) Marking
首先,所有堆中的对象都会被扫描一遍:我们总得知道哪些是垃圾,哪些是有用的物品吧。因为垃圾实在太多了,所以,你妈会把所有的要扔掉的东西都找出来并打上一个标签,到了时机成熟时回头来一起处理,这样她就能处理你不需要的废物、旧家具,而不是把你喜欢的衣服或者身份证之类的东西扔掉。
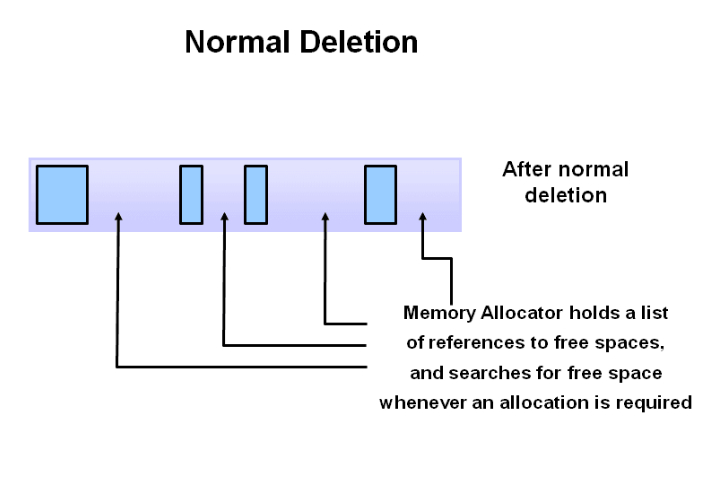
(2) Normal Deletion
垃圾收集器将清除掉标记的对象:你妈已经整理了一部分杂物(或者已全部整理完),然后会将他们直接拎出去倒掉。你很开心房间又可以继续接受蹂躏了。
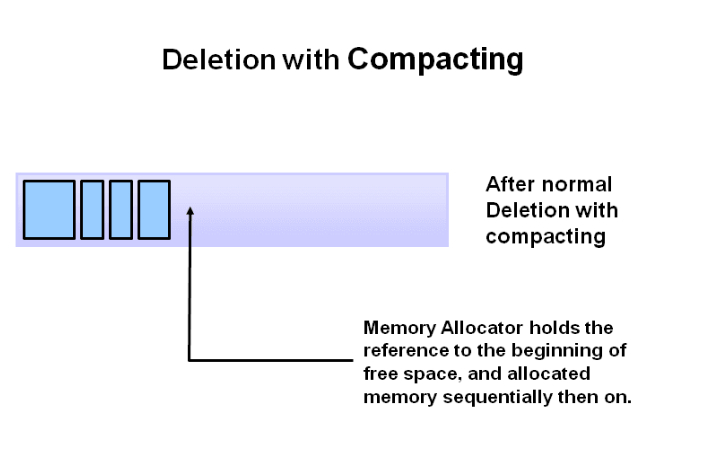
(3) Deletion with Compacting
压缩清除的方法:我们知道,内存有空闲,并不代表着我们就能使用它,例如我们要分配数组这种一段连续空间,假如内存中碎片较多,肯定是行不通的。正如房间可能需要再放一个新的床,但是扔掉旧衣柜后,原来的位置并不能放得下新床,所以需要进行空间压缩,把剩下的家具和物品位置并到一起,这样就能腾出更多的空间啦。
有趣的是,JVM并不是使用类似于objective-c的ARC(Automatic Reference Counting)的方式来引用计数对象,而是使用了叫根搜索算法(GC Root)的方法,基本思想就是选定一些对象作为GC Roots,并组成根对象集合,然后从这些作为GC Roots的对象作为起始点,搜索所走过的引用链(Reference Chain)。如果目标对象到GC Roots是连接着的,我们则称该目标对象是可达的,如果目标对象不可达,则说明目标对象是可以被回收的对象。

GC Root使用的算法是相当复杂的,你不必记住里面的所有细节。但是你要知道的一点就是,可以作为GC Root的对象可以主要分为四种:
1、JVM栈中引用的对象;
2、方法区中,静态属性引用的对象;
3、方法区中,常量引用的对象;
4、本地方法栈中,JNI(即Native方法)引用的对象;
在JDK1.2之后,Java将引用分为强引用、软引用、弱引用、虚引用4种,这4种引用强度依次减弱。
三、分代与GC机制
嗯,听起来这样就可以了?但是实际情况下,很不幸,在JVM中绝大部分对象都是英年早逝的,在编码时大部分堆中的内存都是短暂临时分配的,所以无论是效率还是开销方面,按上面那样进行GC往往是无法满足我们需求的。而且,实际上随着分配的对象增多,GC的时间与开销将会放大。所以,JVM的内存被分为了三个主要部分:新生代,老年代和永久代。
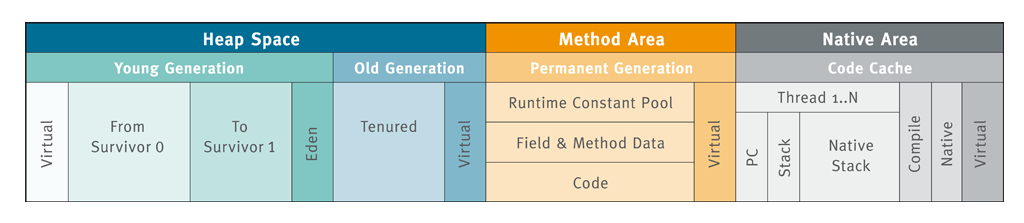
(1)新生代
所有新产生的对象全部都在新生代中,Eden区保存最新的对象,有两个Survivor Space——S1和S0,三个区域的比例大致为8:1:1。当新生代的Eden区满了,将触发一次GC,我们把新生代中的GC称为minor garbage collections。minor garbage collections是一种Stop the world事件,比如你妈在打扫时,会把你赶出去,而不是你一边扔垃圾她一边打扫。
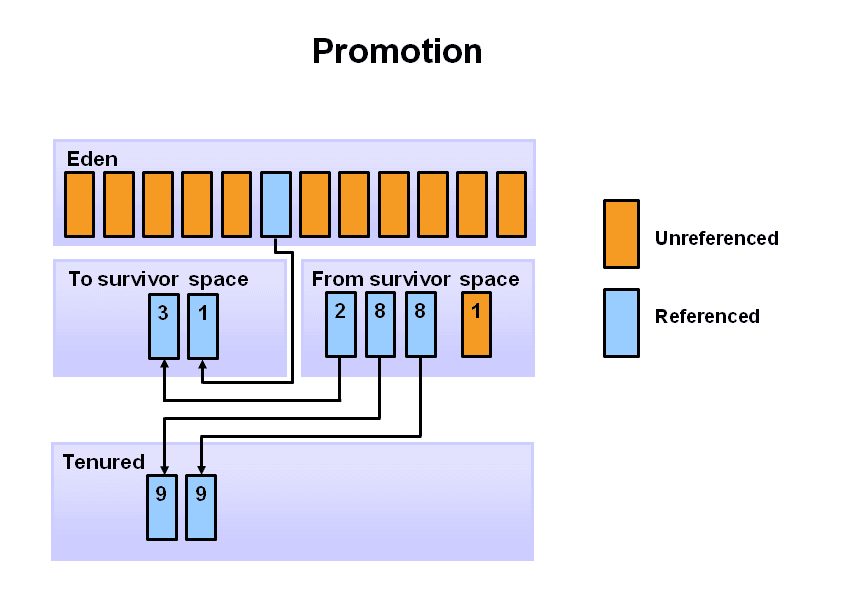
我们来看下对象在堆中的分配过程,首先有新的对象进入时,默认放入新生代的Eden区,S区都是默认为空的。下面对象的数字代表经历了多少次GC,也就是对象的年龄。
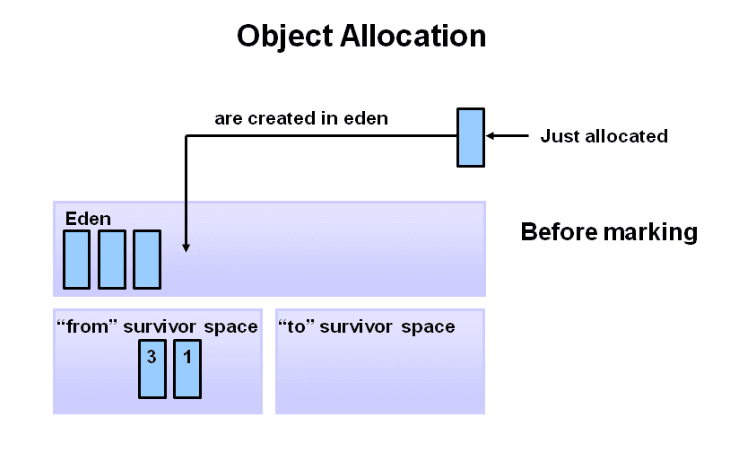
当eden区满了,触发minor garbage collections,这时还有被引用的对象,就会被分配到S0区域,剩下没有被引用的对象就都会被清除。
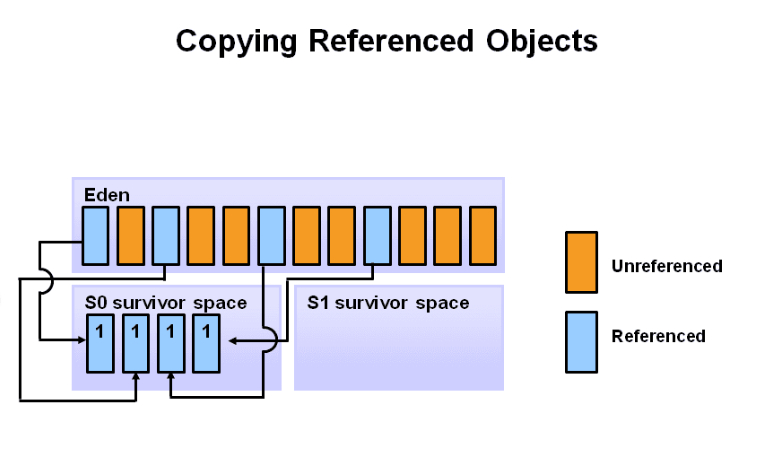
再一次GC时,S0区的部分对象很可能会出现没有引用的,被引用的对象以及S0中的存活对象,会被一起移动到S1中。eden和S0中的未引用对象会被全部清除。
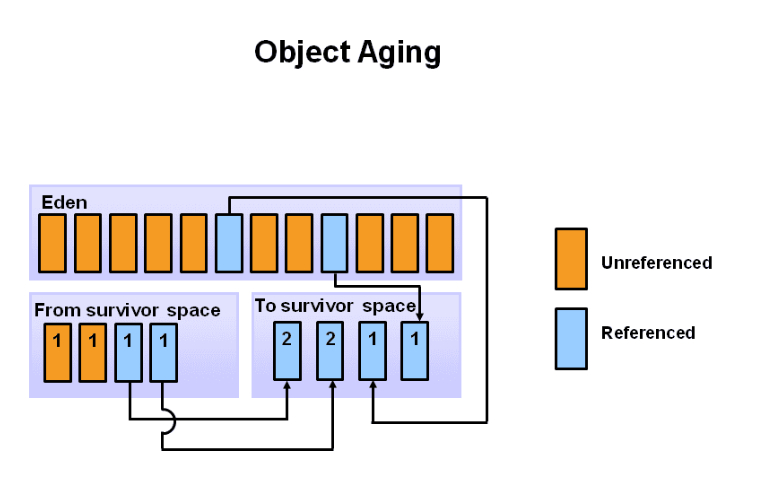
接下来就是无限循环上面的步骤了,当新生代中存活的对象超过了一定的【年龄】,会被分配至老年代的Tenured区中。这个年龄可以通过参数MaxTenuringThreshold设定,默认值为15,图中的例子为8次。
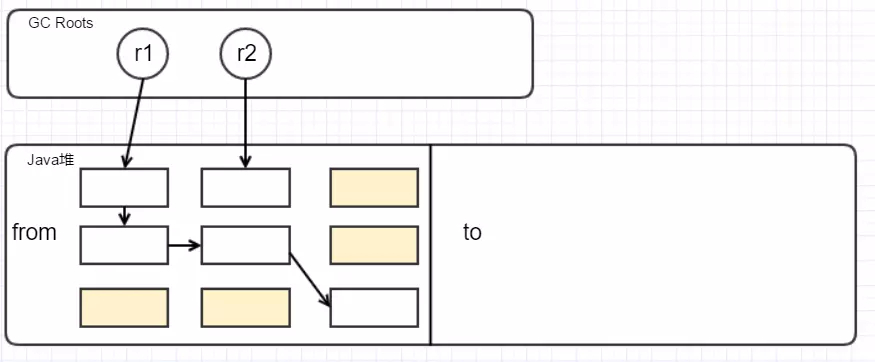
新生代管理内存采用的算法为GC复制算法(Copying GC),也叫标记-复制法,原理是把内存分为两个空间:一个From空间,一个To空间,对象一开始只在From空间分配,To空间是空闲的。GC时把存活的对象从From空间复制粘贴到To空间,之后把To空间变成新的From空间,原来的From空间变成To空间。
首先标记不可达对象:
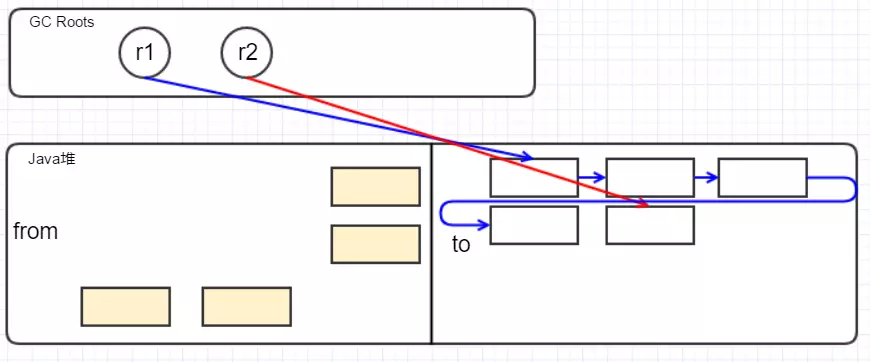
 然后移动存活的对象到to区,并保证他们在内存中连续:
然后移动存活的对象到to区,并保证他们在内存中连续:
 清扫垃圾:
清扫垃圾:
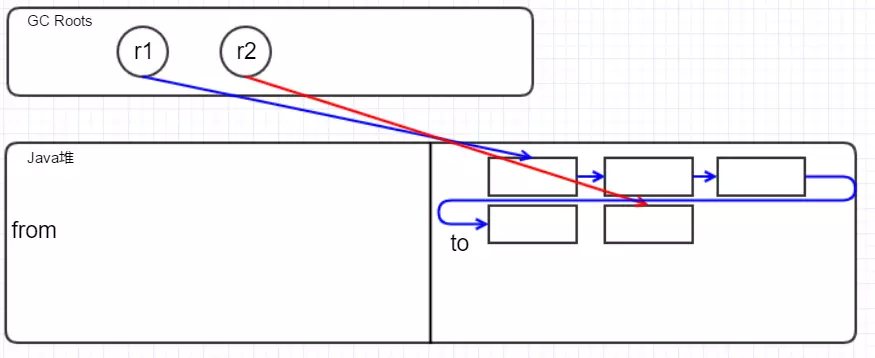
可以看到上图操作后内存几乎都是连续的,所以它的效率是非常高的,但是相对的吞吐量会较大。并且,把内存一分为二,占用了将近一半的可用内存。用一段伪代码来实现大致为下:
void copying(){
$free = $to_start // $free表示To区占用偏移量,每复制成功一个对象obj,
// $free向前移动size(obj)
for(r : $roots)
*r = copy(*r) // 复制成功后返回新的引用
swap($from_start, $to_start) // GC完成后交互From区与To区的指针
}
(2)老年代
老年代用来存储活时间较长的对象,老年代区域的GC是major garbage collection,老年代中的内存不够时,就会触发一次。这也是一个Stop the world事件,但是看名字就知道,这个回收过程会相当慢,因为这包括了对新生代和老年代所有对象的回收,也叫Full GC。
老年代管理内存最早采用的算法为标记-清理算法,这个算法很好理解,结合GC Root的定义,我们会把所有不可达的对象全部标记进行清除。
在清除前,黄色的为不可达对象:
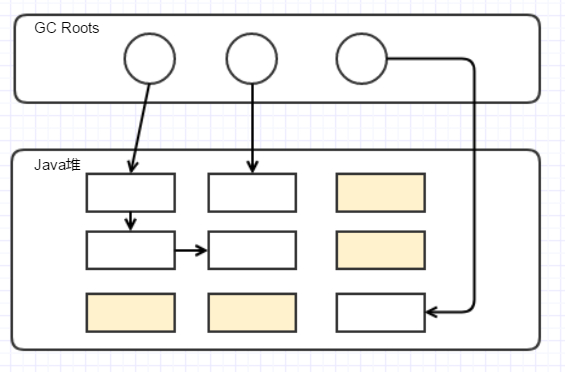
在清除后,全部都变成可达对象:
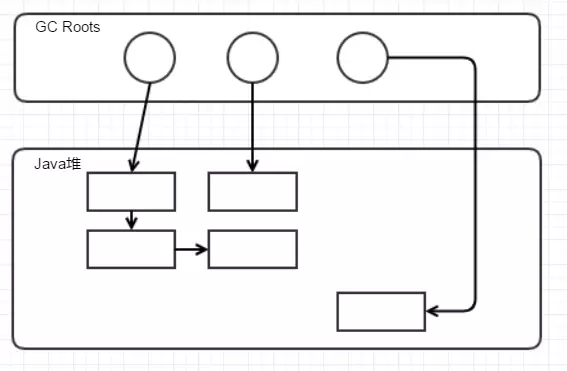
那么,这个算法的劣势很好理解:对,会在标记清除的过程中产生大量的内存碎片,Java在分配内存时通常是按连续内存分配,这样我们会浪费很多内存。所以,现在的JVM GC在老年代都是使用标记-压缩清除方法,将上图在清除后的内存进行整理和压缩,以保证内存连续,虽然这个算法的效率是三种算法里最低的。
(3)永久代
永久代位于方法区,主要存放元数据,例如Class、Method的元信息,与GC要回收的对象其实关系并不是很大,我们可以几乎忽略其对GC的影响。除了Java HotSpot这种较新的虚拟机技术,会回收无用的常量和的类,以免大量运用反射这类频繁自定义ClassLoader的操作时方法区溢出。
四、GC收集器与优化
一般而言,GC不应该成为影响系统性能的瓶颈,我们在评估GC收集器的优劣时一般考虑以下几点:
(1)吞吐量
(2)GC开销
(3)暂停时间
(4)GC频率
(5)堆空间
(6)对象生命周期
所以针对不同的GC收集器,我们要对应我们的应用场景来进行选择和调优,回顾GC的历史,主要有4种GC收集器:Serial、Parallel、CMS和G1。
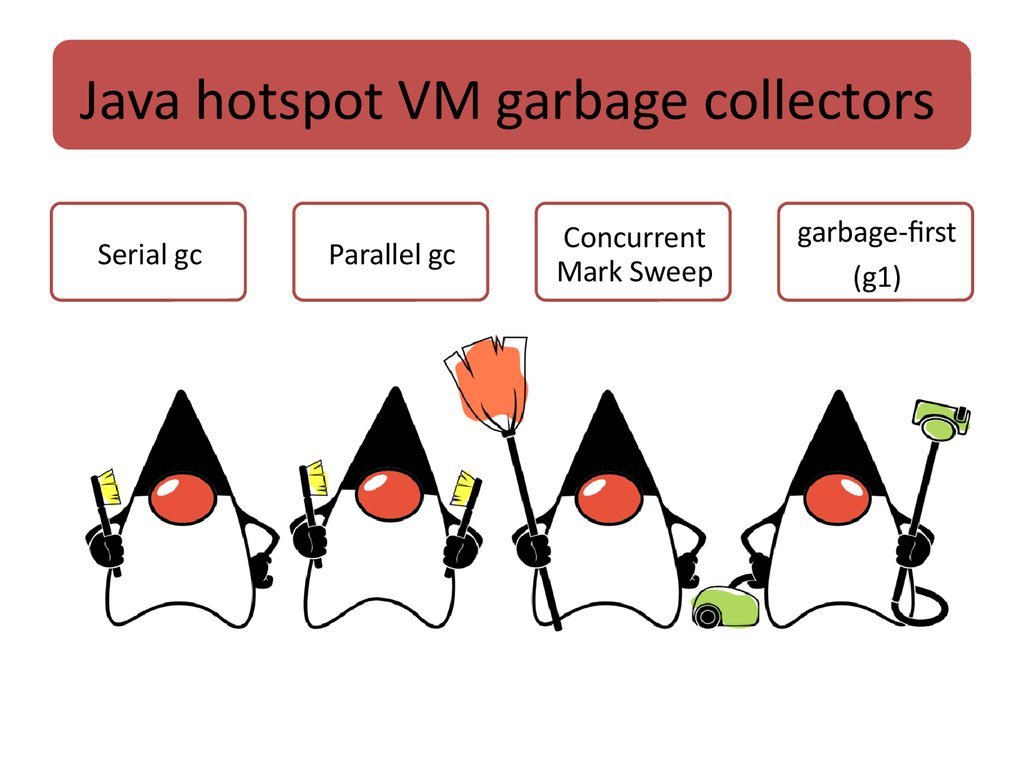
(1)Serial
Serial收集器使用了标记-复制的算法,可以用-XX:+UseSerialGC使用单线程的串行收集器。但是在GC进行时,程序会进入长时间的暂停时间,一般不太建议使用。
(2)Parallel
-XX:+UseParallelGC -XX:+UseParallelOldGC
Parallel也使用了标记-复制的算法,但是我们称之为吞吐量优先的收集器,因为Parallel最主要的优势在于并行使用多线程去完成垃圾清理工作,这样可以充分利用多核的特性,大幅降低gc时间。
当你的程序场景吞吐量较大,例如消息队列这种应用,需要保证有效利用CPU资源,可以忍受一定的停顿时间,可以优先考虑这种方式。
(3)CMS(Concurrent Mark Sweep)
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
CMS使用了标记-清除的算法,当应用尤其重视服务器的响应速度(比如Apiserver),希望系统停顿时间最短,以给用户带来较好的体验,那么可以选择CMS。CMS收集器在Minor GC时会暂停所有的应用线程,并以多线程的方式进行垃圾回收。在Full GC时不暂停应用线程,而是使用若干个后台线程定期的对老年代空间进行扫描,及时回收其中不再使用的对象。
(4)G1(Garbage First)
-XX:+UseG1GC
在堆比较大的时候,如果full gc频繁,会导致停顿,并且调用方阻塞、超时、甚至雪崩的情况出现,所以降低full gc的发生频率和需要时间,非常有必要。G1的诞生正是为了降低Full GC的次数,而相较于CMS,G1使用了标记-压缩清除算法,这可以大大降低较大内存(4GB以上)GC时产生的内存碎片。
G1提供了两种GC模式,Young GC和Mixed GC,两种都是Stop The World(STW)的。Young GC主要是对Eden区进行GC,Mix GC不仅进行正常的新生代垃圾收集,同时也回收部分后台扫描线程标记的老年代分区。
另外有趣的一点,G1将新生代、老年代的物理空间划分取消了,而是将堆划分为若干个区域(region),每个大小都为2的倍数且大小全部一致,最多有2000个。除此之外,G1专门划分了一个Humongous区,它用来专门存放超过一个region 50%大小的巨型对象。在正常的处理过程中,对象从一个区域复制到另外一个区域,同时也完成了堆的压缩。
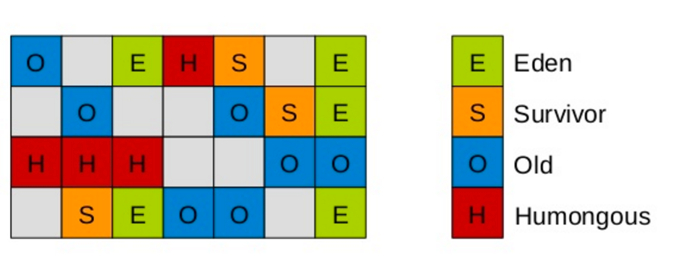
(5)常用参数
-XX:+UseSerialGC:在新生代和老年代使用串行收集器
-XX:+UseParNewGC:在新生代使用并行收集器
-XX:+UseParallelGC :新生代使用并行回收收集器,更加关注吞吐量
-XX:+UseParallelOldGC:老年代使用并行回收收集器
-XX:ParallelGCThreads:设置用于垃圾回收的线程数
-XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用CMS+串行收集器
-XX:ParallelCMSThreads:设定CMS的线程数量
-XX:+UseG1GC:启用G1垃圾回收器
(6)调优
针对调优这块,推荐可以看下美团点评的这个GC实战调优案例:《从实际案例聊聊Java应用的GC优化》。里面详细讲述了Minor GC频繁、CMS高峰期性能下降、Stop-The-World三个应用场景的问题分析过程,以及在应用程序编码优化空间不大的情况下,如何通过GC优化令系统性能达到一个质的提升。